
模型以及数据积累是UBI核心壁垒
相关报告
- 2015-2020年中国湿电子化学品行业市场重点层面调查研究报告(2015-10-09)
- 2016-2022年中国车联网导航行业市场深度调查研究及投资咨询报告(2015-11-30)
- 2014-2018年中国车联网设备行业市场深度调查研究及投资前景咨询研究报告(2014-01-16)
- 2014-2018年车联网行业深度调研分析及投资前景研究报告(2013-12-31)
- 2015-2020年中国湿电子化学品行业市场主要领域调查分析报告(2015-10-09)
- 2015-2020年中国电子化学品行业市场深度调查研究及投资前景分析报告(2015-03-10)
- 2014-2018年中国车联网行业市场深度剖析及投资前景趋势研究报告(2014-01-05)
- 2015-2020年中国电子化学材料行业市场主要领域调查分析报告(2015-09-14)
- 2015-2020年中国电子化学材料行业市场深度剖析及投资发展研究报告(2015-07-31)
- 2015-2020年中国电子化学品行业市场深度调查分析及投资战略研究报告(2015-03-10)
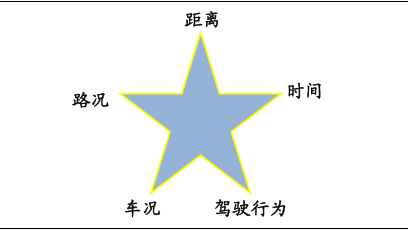
UBI的核心壁垒在于数据积累与模型。对大部分采用UBI计算的保险公司来说,驾驶风险模型会用到20个以上的参数,包括车主驾驶的距离(里程数)、车主驾驶的质量(急加速、急刹车、转弯、调头)、车主驾驶的节点(驾驶的时间)、路况四方面。
由于UBI模型具有迭代更新的特点,因此数据量以及模型迭代次数至关重要。一般情况,成熟的UBI模型需要100万以上的有效数据,迭代时间超过6个月。据我们产业链跟踪的结果,国内能做到百万级数据量只有翼卡、Onstar、车宝、得润电子(其并购意大利UBI公司数据量应该也过百万)4家。(Progressive从2009年开始,用了6年时间用户数也只有250万)
驾驶风险五星准则
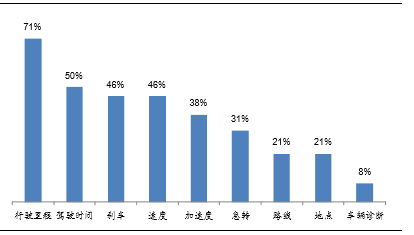
UBI所用参数权重(不同模型参数权重不同)
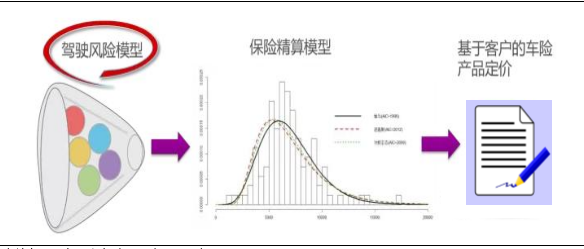
保险公司利用UBI,会构建两个分析模型,一个是驾驶风险模型,一个是基于驾驶风险和其他风险的保险定价模型。驾驶风险模型是拥有车联网数据的企业可以进行挖掘的部分。最终的模型结果是给出用户评级,而保险公司基于评级进行车险定价。
UBI车险定价模型
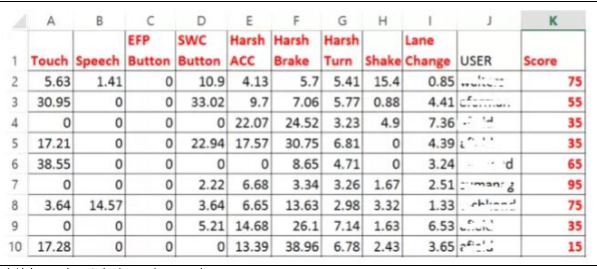
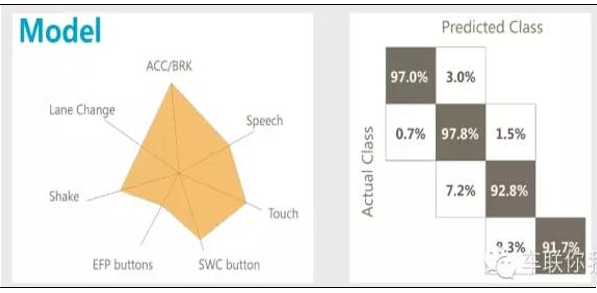
经过驾驶风险模型打分后结果示例
由于数据量庞大且混合(规则、半规则),驾驶风险模型一般采用云的机器学习(MachineLearning)。
机器学习迭代由两部分组成。第一步进行云平台验证,在保险公司的协助下,从UBI的车主中选取出险理赔的红蓝匹配样本,抽取特征值,从而在云平台构建业务模型(神经网络/决策树等);之后数据导入,进行云平台运算,校验模型和精算分析进行沟通,确定驾驶风险输出的可用性,并最终确定对驾驶风险影响的因子及其关系。
云平台验证确定对驾驶风险影响的因子及其关系
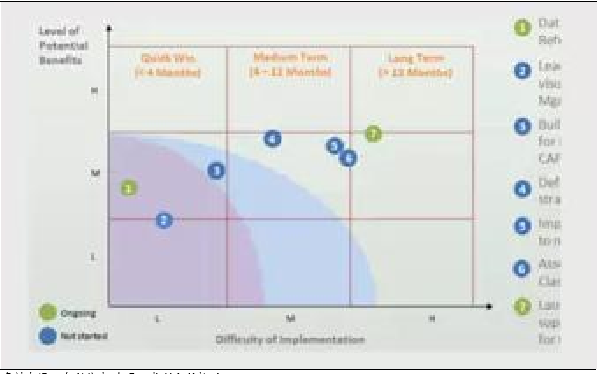
迭代过程的第二步是形成模型基准。根据云平台的验证结果,建立驾驶风险的评分模型明确和其他数据的(例如理赔)的集成和协同关系、建立通过驾驶风险进行骗保、客户分群的整体架构、研究其他UBI保险驾驶风险模型的实施路径,最终进行蓝图设计,明确驾驶风险模型完善实施的规划。
通过上述机器运算对大量数据反复迭代,不断提升模型的准确性。
进行蓝图设计,明确驾驶风险模型完善实施的规划
本文地址:http://www.zwzyzx.com/show-333-214387-1.html
相关资讯
- 全球轮胎研发投入逐步提高,创新产品日趋多元化(2014-06-29)
- 乘用车和商用车可进一步细分情况介绍(2015-05-03)
- 驾驶环境探测的相兲技术尚不成熟,车联网通信技术与标准也未明确(2016-09-21)
- 软轴式变速控制系统由四个模块构成(2014-10-15)
- 中国客车出口已连涨5年,需要适当调整(2016-03-27)
- 汽车电子的分类情况(2015-07-08)
- 世界汽车行业发展情况(2015-07-28)
- 国内铝合金车轮行业管理体制及主管部门(2015-07-31)
合作媒体
最新报告
定制出版
热门报告
免责声明
中为咨询所引述的资料是用于行业市场研究以及讨论和交流,并注明出处,部分内容是由相关机构提供。若有异议请及时联系本公司,我们将立即依据相关法律对文章进行删除或作相应处理。查看详细》》
