
CPU性能指数提升,伴随GPU、云计算等新型计算形态出现
相关报告
- 数据更新中...
从技术发展看,摩尔定律推动CPU性能指数提升,伴随GPU、云计算等新型计算形态出现。通过观察近些年深度学习相关的案例,在提升计算能力上除了使用传统的CPU,还引入对单个可并行计算任务处理更为擅长的GPU,随后更是有云计算、网格计算等分布式并行处理技术的出现。
GPU在深度学习中表现出超越CPU的优势并得到广泛使用
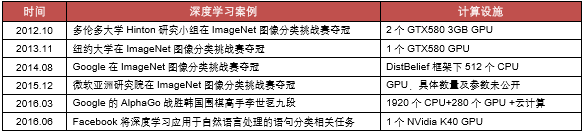
①、过去十年,CPU性能大致按照摩尔定律指数式提升。摩尔定律可以说是整个计算机行业最重
要的定律,它预言每两年微处理器的晶体管数量都将加倍,换言之就是芯片的处理能力每两年增加一倍。这种指数级的增长,使得21世纪以来计算机比起九十年代快了数十倍,大型数据集和多层的学习更易于处理。
②、CPU性能提升陷入瓶颈,但是GPU以及云计算、网格计算等新的计算形态出现。对CPU而言,一方面在摩尔定律指导下同样小的空间集成越来越多的硅电路,发热越来越大,开始抵达提升上限;另一方面,单个CPU串行处理任务的特点限制了其在深度学习领域的应用,性能的提升主要通过多个CPU并行,但单纯堆砌大量CPU会造成网络通信延迟,堆得越多速度越慢。而GPU作为一种图形处理器芯片,在浮点运算、并行计算等方面同样拥有数十倍乃至上百倍于CPU的性能,其强大的并行运算能力擅长于处理大规模单个可并行任务。
此外,GPU与云计算、网格计算等分布式并行处理技术结合,更是大幅度提高了计算能力。一般意义上基于CPU的云计算,主要通过网络传输CPU的运算能力,为客户端返回计算结果或者文件。而GPU云计算则更擅长图形渲染运算或大规模并行计算。近些年NVIDIA、Amazon、阿里等相继推出GPU云计算平台并对外提供服务。据测算,假如有200万张图片需要学习,用一台双路E5-2650v2的服务器训练需要16天时间,而如果用阿里云双GPU物理机仅需要1天。
NVIDIA/Amazon/阿里等相继推出GPU云计算平台并对外提供服务

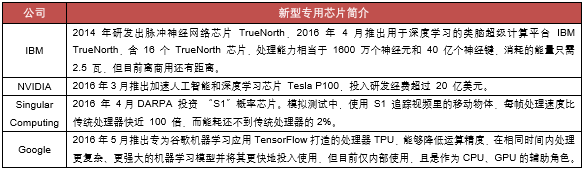
③、深度学习专用芯片研发开始兴起,更高的集成度+更低的能耗成为目标方向。据媒体报道,AlphaGo下一盘棋仅散热耗电就近3000美元。单纯从能效比来看,我国超级计算机“天河一号”和“天河二号”每瓦特运算次数分别为4.3亿次和19亿次,而IBM在2016年4月推出用于深度学习的类脑超级计算平台IBMTrueNorth每瓦特突触运算数为460亿次,能耗远远低于当前其他超级计算机。除了能效方便对比较为明显,在应对大量数据的输入缓冲等方面专用芯片也有优势。IBM、NVIDIA、Google等在专用芯片方面已经开始有所布局。虽然就目前而言专用芯片更多还是以辅助的角色出现配合CPU、GPU,但未来值得期待。
神经网络/深度学习专用芯片或将大幅降低超级计算机能耗
本文地址:http://www.zwzyzx.com/show-269-224880-1.html
相关资讯
- 我国铁路行车安全系统行业的周期性、区域性和季节性特征(2014-05-29)
- 互联网增量机会:仍有一半以上的人口尚未联网,未来仍有较大增量(2016-10-13)
- 国内信息安全行业取得认证需具备的条件(2014-12-08)
- 射频同轴电缆在新兴行业方面也具有广阔的市场空间(2015-06-02)
- 2014年至2018年全球卡片存量发展趋势图(2015-07-17)
- 软件行业主要商业模式(2016-10-08)
- MEMS传感器在物联网领域的应用(2016-10-08)
- 国内建筑装饰行业的技术水平及特点(2015-04-13)
合作媒体
最新报告
定制出版
热门报告
免责声明
中为咨询所引述的资料是用于行业市场研究以及讨论和交流,并注明出处,部分内容是由相关机构提供。若有异议请及时联系本公司,我们将立即依据相关法律对文章进行删除或作相应处理。查看详细》》
