
自然语言处理方法及分析
相关报告
- 数据更新中...
自然语言存在的形式主要包括语音和文本两种形式,所谓自然语言处理,简单说也就是识别出语音
和文本,并能以语音或文本的形式再表达出来。衡量处理效果的指标主要就是准确性,包括形式上识别的准确性,和语法、语义的准确性以及是否符合人类使用习惯和情境需要。下面以深度学习在语音识别和语义分析方面的应用为例加以说明:
1、语音识别
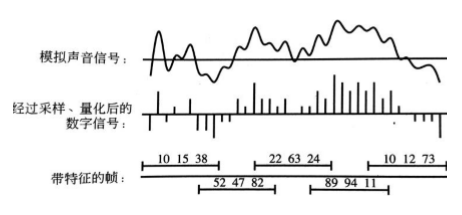
传统语音识别方法:语音识别只需要判断出所说的词是什么就可以从语料库直接调取。语言学家定义了大约100种话语声音,称之为“音节”,这些音节几乎可以组合成已知的所有人类语言中的所有词汇。模拟声音信号经过采样和量化以后转化为数字信号,语音识别系统按照时间顺序将数字信号切割成带有特征的小片,然后转化成向量表示方式并与语料库进行匹配,通过不断的循环迭代优化,最终选取可能性最大的音节从而组合成词句。
模拟声音信号波形
声学信号转化为特征向量
深度学习下的语音识别:2009年Hinton开始把多层神经网络介绍给语音识别的研究学者们,将传统方法替换成深度神经网络以后,2010年语音识别错误率降低了20%以上。最主要的变化就是通过深度神经网络学习采样量化后的声音信号并自动提取更为丰富也更为复杂的特征取代原来使用的人工设定的音节特征。后来语音识别就几乎一直处于深度学习的框架下,利用更多的数据和更好的模型不断改进,目前科大讯飞在常用场景下准确率已经超过98%,业内领先。
【语音识别案例】科大讯飞自然语言处理产品
科大讯飞自然语言处理产品
2、语义分析
传统的自然语言处理方法在问答系统,机器翻译等语义分析应用中,主要通过事先针对文本人为设
计好标注特征,处理时通过对文本数据中包含的这些人工设计好的特征传递给计算机并进行权值的数学优化。
而深度学习通过将自然语言文本中词语、短语、句子等切割并以连续实值向量的形式表示(在专业
领域称为“嵌入”),自动从原始文本中学习并提取能广泛适用于各种自然语言处理任务的特征,从而完成语言翻译、为图片添加描述以及用文字回答问题等任务。
具体而言,当词句被表示成连续实值向量以后便于对相同含义的词语进行共享或聚类。每一个词语
的上下文都将作为深度神经网络的学习信号,然后通过无监督学习的方法进行训练,自动提取出文
本特征。由于结合考虑了局部甚至全局的上下文信息,深度学习能更好地获取文本词义。针对每个词句使用多种“嵌入”方式则可以解释同音异义、一词多义等现象。
【语义分析案例】Google翻译
2016年3月份Google在洛杉矶结构数据会议上提到正在尝试将深度学习融入到Google翻译中以进一步提高翻译准确率。
Google翻译将引入深度学习以提高准确率

本文地址:http://www.zwzyzx.com/show-336-224891-1.html
上一篇:基于深度学习的人工智能应用
下一篇:图像识别与视频分析简介
相关资讯
- 遥望网络(834448):流量聚合、手游公会双轮驱动,布局手游生态链(2016-09-22)
- 医疗卫生信息化行业重要产业政策情况(2014-08-05)
- 国内网游加速服务行业特有的经营模式(2015-02-06)
- 影响软件及IT服务行业发展的有利和不利因素(2015-09-06)
- 光通信行业概述(2016-06-08)
- 移动终端设备与上、下游行业之间的关联性(2016-03-04)
- 我国互联网视频服务行业主要产业政策和法规(2014-05-31)
- 影响有线电视系统行业发展的有利和不利因素 (2015-08-27)
合作媒体
最新报告
定制出版
热门报告
免责声明
中为咨询所引述的资料是用于行业市场研究以及讨论和交流,并注明出处,部分内容是由相关机构提供。若有异议请及时联系本公司,我们将立即依据相关法律对文章进行删除或作相应处理。查看详细》》
