
深度学习基本原理介绍
相关报告
- 数据更新中...
与神经网络的“误差反向传播“不同,深度学习的基本思想包括如下三方面:
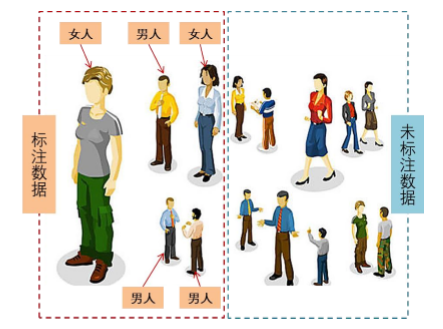
①、不要求训练样本输入输出一一匹配,自动寻找数据特征:根据样本是否被人工添加过分类标签
可以将其划分为标注样本和非标注样本。之前神经网络算法要求输入数据事先经过人工对其特征进行标注,深度学习可以从一组未标记的数据中自动找到某些隐藏的结构与特征。
标注数据VS未标注数据
②、非监督学习逐层预训练得到初始参数:简单地说,从已经人为给定特征分类标记的数据中学习
称之为监督学习,从未标记的数据中自动习得一些隐藏特征称为非监督学习。深度学习采用的方法
是,将多层神经网络的隐层逐层“切片”,以非监督学习的方式挨个学习,并将当前隐层的输出作为下一个隐层的输入,以此类推直到确定好所有隐层对应的权值、阈值等参数作为初始值,至此隐层预训练完毕。
③、监督学习结尾+误差反向传播寻优:隐层预训练完毕到最后输出层时转为监督学习,按照样本
③、监督学习结尾+误差反向传播寻优:隐层预训练完毕到最后输出层时转为监督学习,按照样本
的实际分类计算输出结果与实际结果之间的误差,然后采用“误差反向传播算法”,将误差沿着“输
出→输入”的方向逐层分配给前一层,通过优化技巧找出整体误差最小化的方案,从而完成训练。
深度学习基本原理示意图
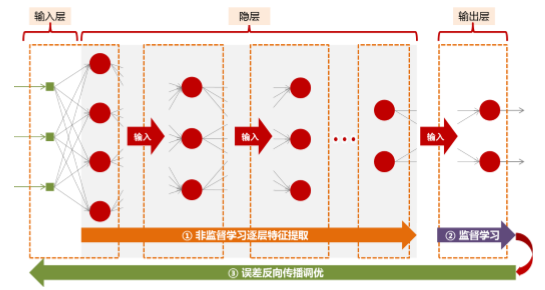
正如上图所示,深度学习第一阶段按照“输入层→最后一个隐层”的方向自下而上通过无监督学习方式逐层提取特征,第二阶段“最后一个隐层→输出层”通过监督学习计算当前整个网络结构的累积总误差,第三阶段按照“输出层→输入层”的方向自上而下通过误差反向传播算法调优。整个相当于将大量待定的参数通过分组预训练并找到每组的局部最优,然后在所有局部最优的基础上寻找全局最优。
以图像识别为例,通过深度学习对大量未标注的图片进行学习,在划分的许多中间隐层中,从直观上来看或许往往对应着图片的某些抽象特征。例如曾经有人构造了一个9层卷积神经网络,共65万个神经元,6千万个参数。输入是未标注的大量图片,输出为1000个物体的类别。其他人在此基础上研究发现,第一层神经元主要负责识别颜色和简单纹理,第二层神经元可以识别更为细化的纹理,第三层神经元负责感受光感变化等。事实上这些特征都是机器自动习得,而非人为标注。
本文地址:http://www.zwzyzx.com/show-269-224865-1.html
上一篇:深度学习正式面世并持续发展
相关资讯
- 计算机仿真技术情况简介(2015-09-01)
- 国内进入数据中心行业的主要壁垒(2015-05-03)
- 中国智能家居行业IC芯片应用发展情况(2016-01-13)
- 工业和信息化部发放第二批移动通信转售业务试点批文(2014-02-24)
- 系统集成新风口看3C行业(2016-09-05)
- 国内商业智能系统的市场规模持续增长(2015-04-11)
- 我国3D网络游戏的市场状况(2015-04-30)
- TrendMicro:积极转型移动安全、云安全、APT防护,成绩喜人(2016-07-29)
合作媒体
最新报告
定制出版
热门报告
免责声明
中为咨询所引述的资料是用于行业市场研究以及讨论和交流,并注明出处,部分内容是由相关机构提供。若有异议请及时联系本公司,我们将立即依据相关法律对文章进行删除或作相应处理。查看详细》》
